Data sets from different sources are rarely uniform. This means in order to merge or combine data sets from different sources we have to do data cleanup. One of the common U.S. data source issues I encounter is State Name vs State Abbreviation. In this notebook, we will look at an easy way to gather state/abbreviation information for use in other analyses.
For this data set, we will use data from usps.com. I had some issues with their website causing multiple redirects when attempting to access the data. To work around this I began including a standard request header in my request
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
}
Using the standard requests library I extracted the needed data from https://pe.usps.com/text/pub28/28apb.htm
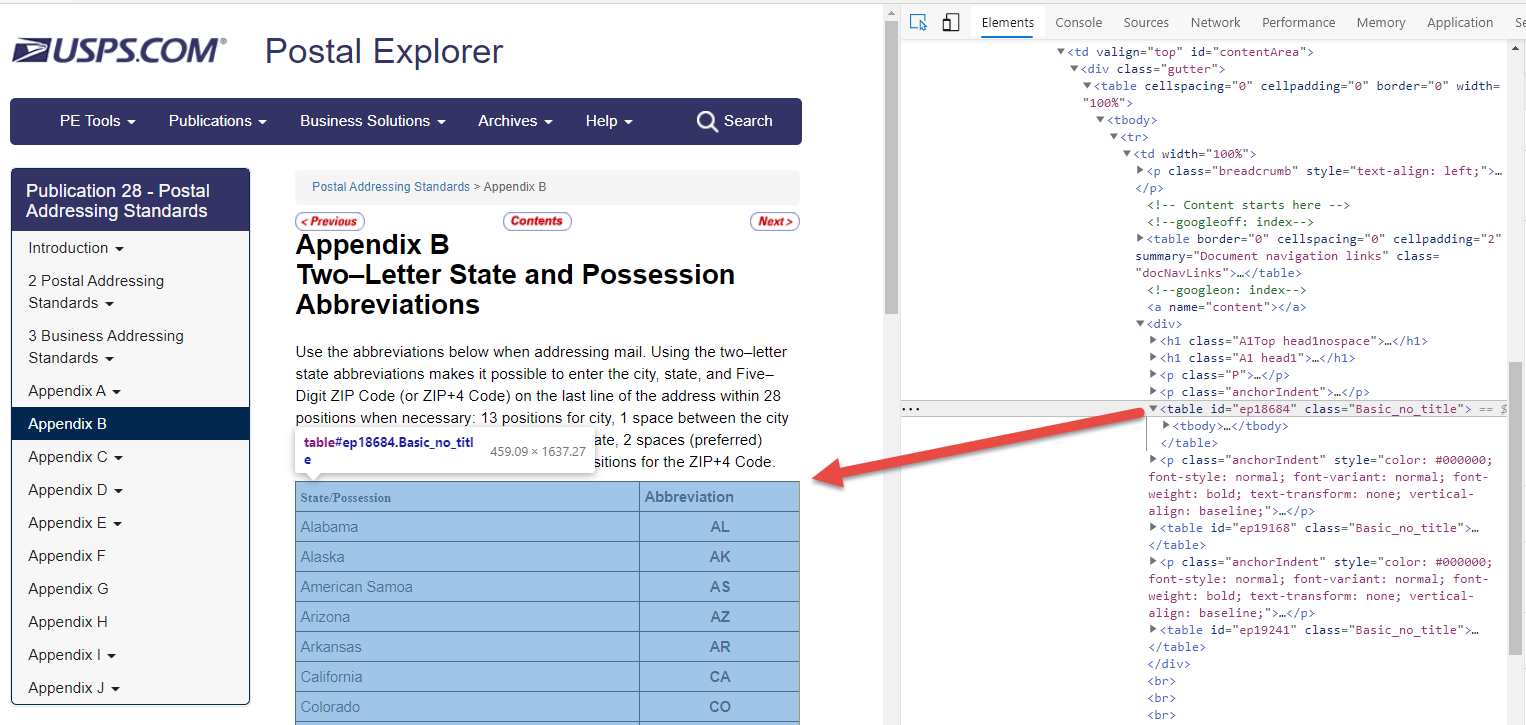
Using the MS Edge developer tools I found that the needed HTML table had an id of ep18684.
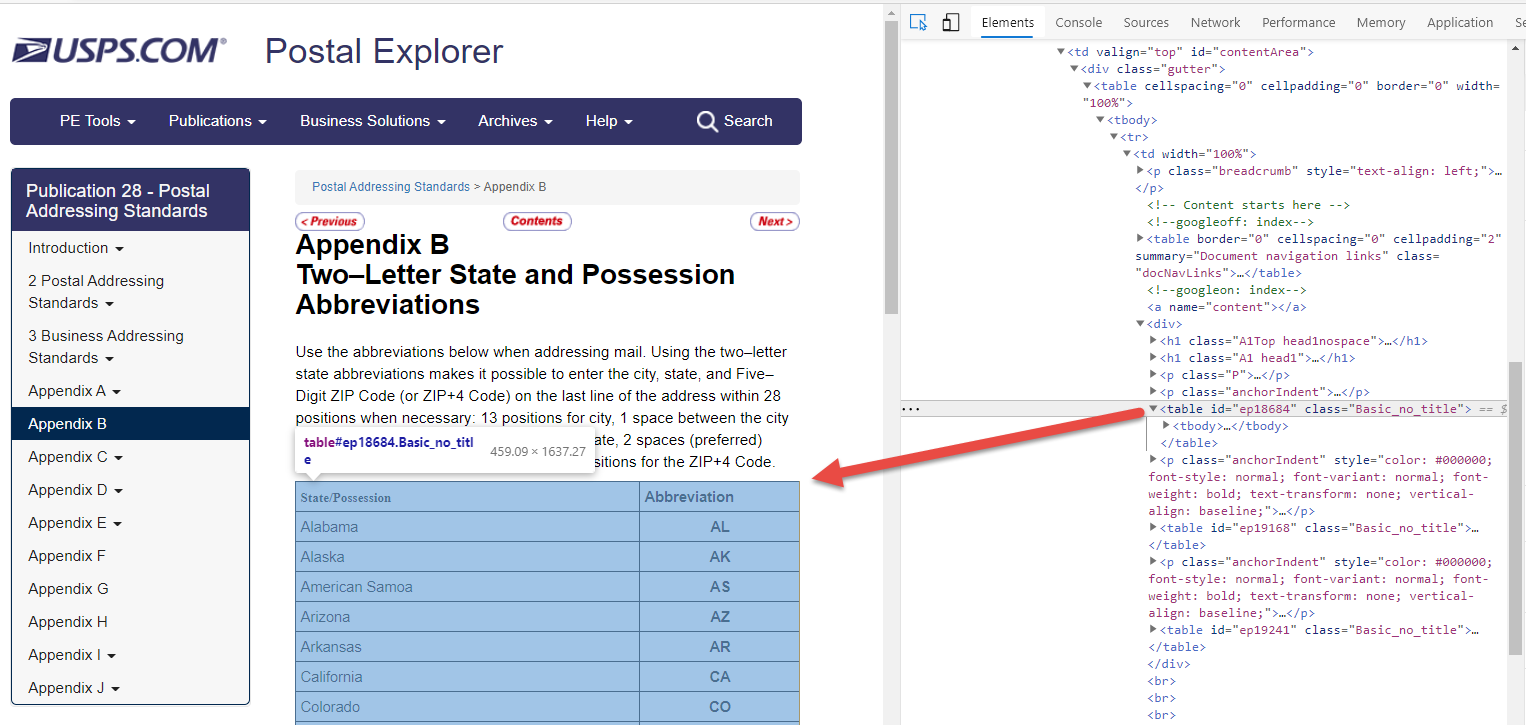
After identifying this table it is very easy to make an HTTP request and using beautiful soup, extract the exact information needed.
import bs4 as bs
import requests
resp = requests.get('https://pe.usps.com/text/pub28/28apb.htm', headers=headers)
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'id': 'ep18684'})
At this point, the table is still an HTML table so now we need to convert it to a more usable format. This could be a dictionary, JSON, XML or my favorite, a pandas dataframe. Using pandas extract the data from the table object and place it in a dataframe. In this case, I manually stipulated the column names, but we could very easily extract column names from the table object as well.
import pandas as pd
df = pd.read_html(str(table))[0]
df = df.iloc[1:]
df.columns = ['State', 'Abbreviation']
df.head(10)
| State | Abbreviation | |
|---|---|---|
| 1 | Alabama | AL |
| 2 | Alaska | AK |
| 3 | American Samoa | AS |
| 4 | Arizona | AZ |
| 5 | Arkansas | AR |
| 6 | California | CA |
| 7 | Colorado | CO |
| 8 | Connecticut | CT |
| 9 | Delaware | DE |
| 10 | District of Columbia | DC |
We now have a table that can be used to merge datasets using state abbreviation with datasets using full state name
Tying it all together
import pandas as pd
import bs4 as bs
import requests
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
}
resp = requests.get('https://pe.usps.com/text/pub28/28apb.htm', headers=headers)
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'id': 'ep18684'})
df = pd.read_html(str(table))[0]
df = df.iloc[1:]
df.columns = ['State', 'Abbreviation']
df.head(10)
| State | Abbreviation | |
|---|---|---|
| 1 | Alabama | AL |
| 2 | Alaska | AK |
| 3 | American Samoa | AS |
| 4 | Arizona | AZ |
| 5 | Arkansas | AR |
| 6 | California | CA |
| 7 | Colorado | CO |
| 8 | Connecticut | CT |
| 9 | Delaware | DE |
| 10 | District of Columbia | DC |
![]()
